| LandingLens | LandingLens on Snowflake |
|---|---|
is a paradigm shift in the field of computer vision. You label only a few small areas of an object in a few images, and the model almost immediately detects the whole object in all of your images. In most cases, the model’s predictions aren’t 100% accurate the first time around, but you can easily label a few more small areas, re-run the model, and check your results.
is a highly accurate and fast model that enables you to quickly create and deploy your own custom computer vision model.
Because of its speed and ease of use, we encourage you to try before creating any other project type.
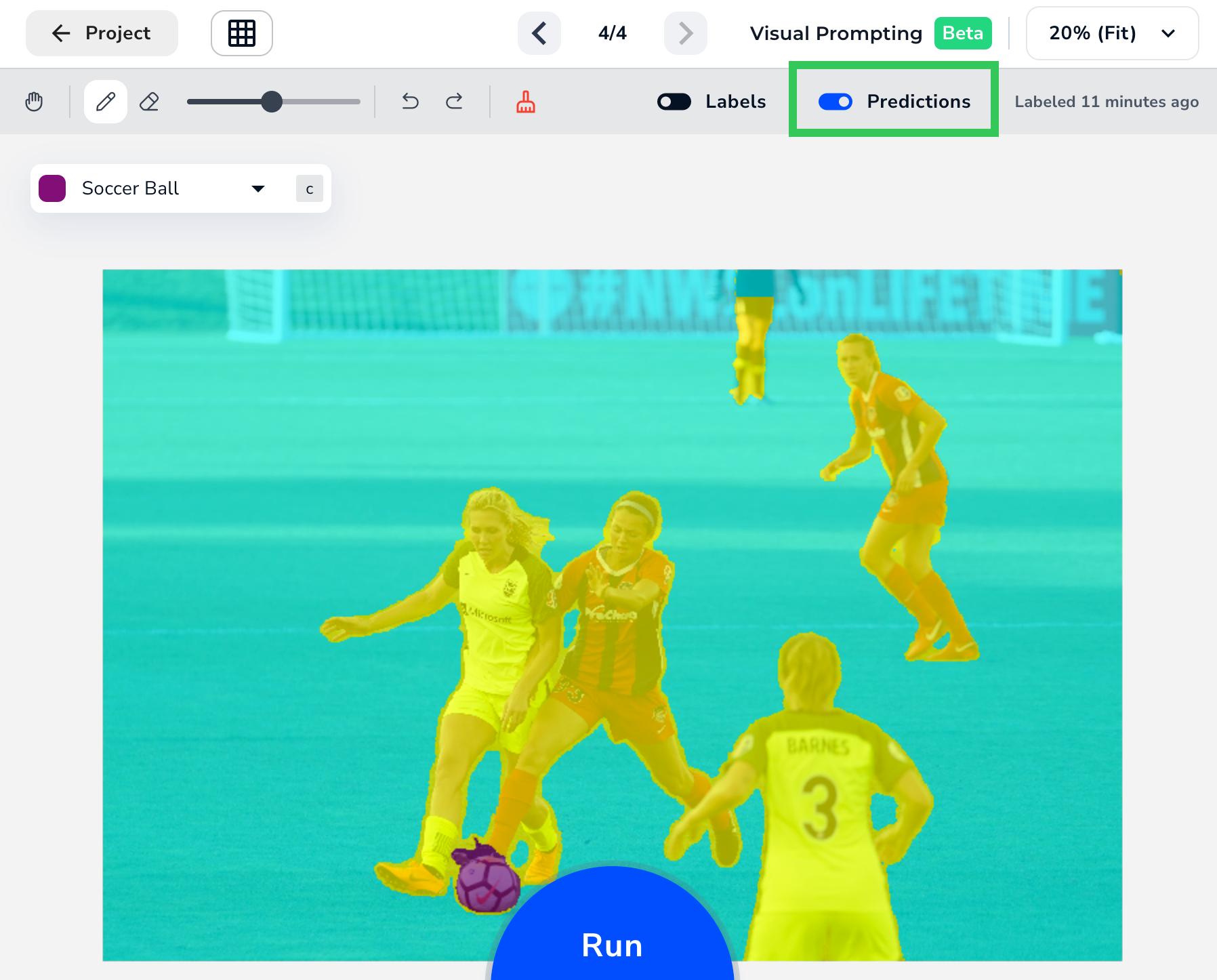
Visual Prompting is in Beta. It might not function as well as our other production-ready features.
What does the phrase “” mean?
In the field of artificial intelligence (AI), prompting refers to providing input to an AI model for that model to generate a response. It’s like prompting a person to answer a question, or giving a student a prompt to write an essay about. You might have already heard about AI prompting without realizing what it was called. For example, the popular chatbot ChatGPT relies on prompting: you ask ChatGPT a question or tell it to describe something, and the Model responds. The application DALL-E is similar: you describe what you want to see, and the Model generates a digital image based on your description. Both of these types of applications rely on textual prompts; you need to write a sentence or series of words for the AI Model to work. ChatGPT has a text-to-text workflow, and DALL-E has a text-to-image workflow. Now, with the release of , has introduced an image-to-image AI prompting workflow. You give a visual prompt to the model, and it provides a visual output. In practice, you label a small section of an object in an image, and model is able to detect the whole object you marked, not just in the original image, but in others too. is the next step in broadening the applications of AI prompting. is not associated with ChatGPT or DALL-E.
Workflow
The workflow is an iterative process. After you label your first image, run your model. When you see the results, fine-tune your labels and re-run the model. It is normal for this process of re-labeling and re-running to occur a few times before your model is ready to be deployed. models run quickly, so even though this is an iterative process, you will be able to deploy even complex models in minutes. Here’s an overview of the workflow:- Upload images
- Label small portions of an image. Use at least two classes.
- Click Run.
- Review the predictions of that image.
- If the results aren’t quite right yet, fine-tune your labeling and run the model again. Repeat until you’re happy with the results.
- Deploy the model.
Label Images
If you’ve created computer vision projects before, you’ll immediately notice that labeling images with is drastically different—and easier and cooler—than with those other projects. Because of the powerful and intuitive algorithms built into , you only need to label a few small areas to get lightning-fast accurate results. Projects support a maximum of 25 images.
Accurately Label Small Areas
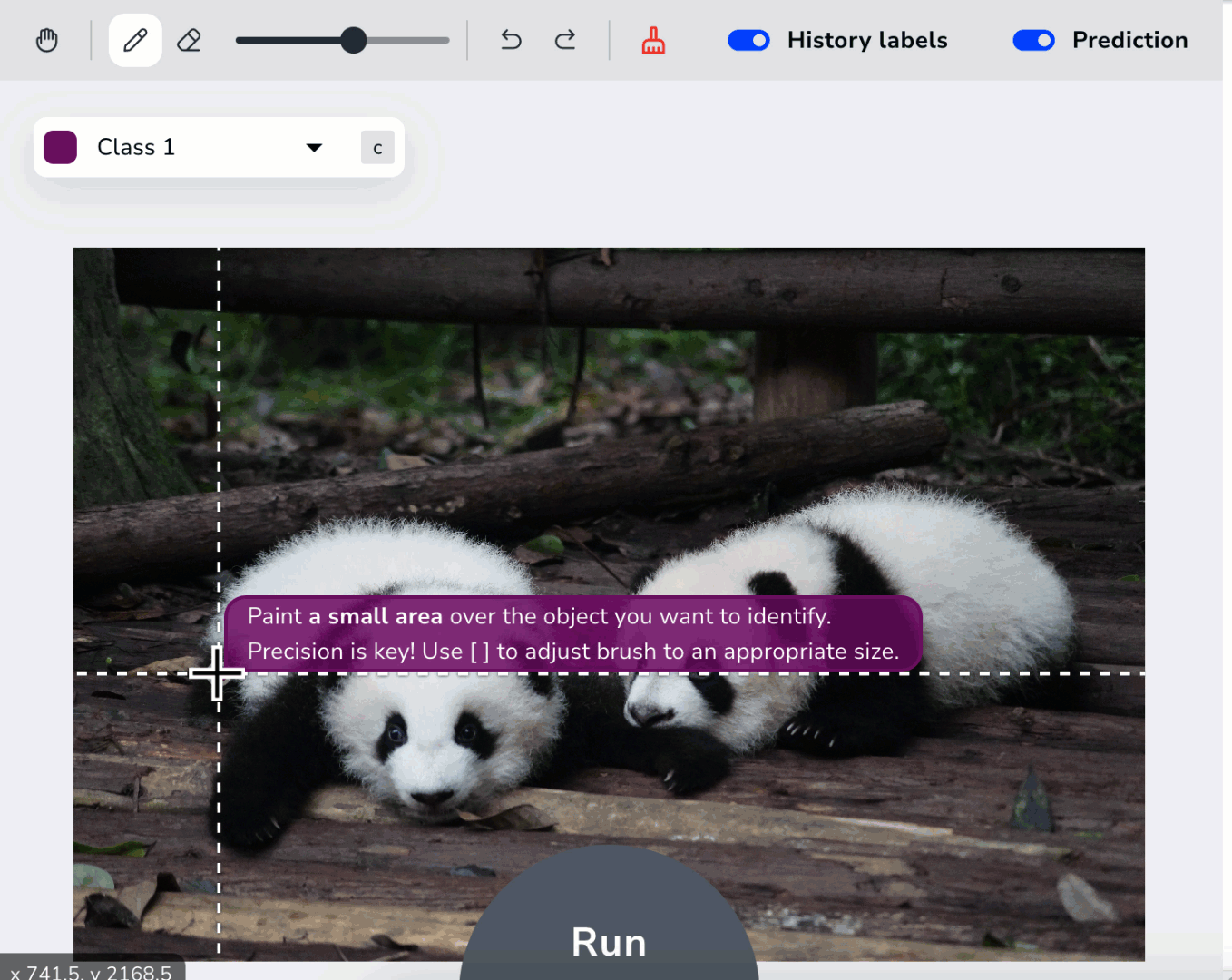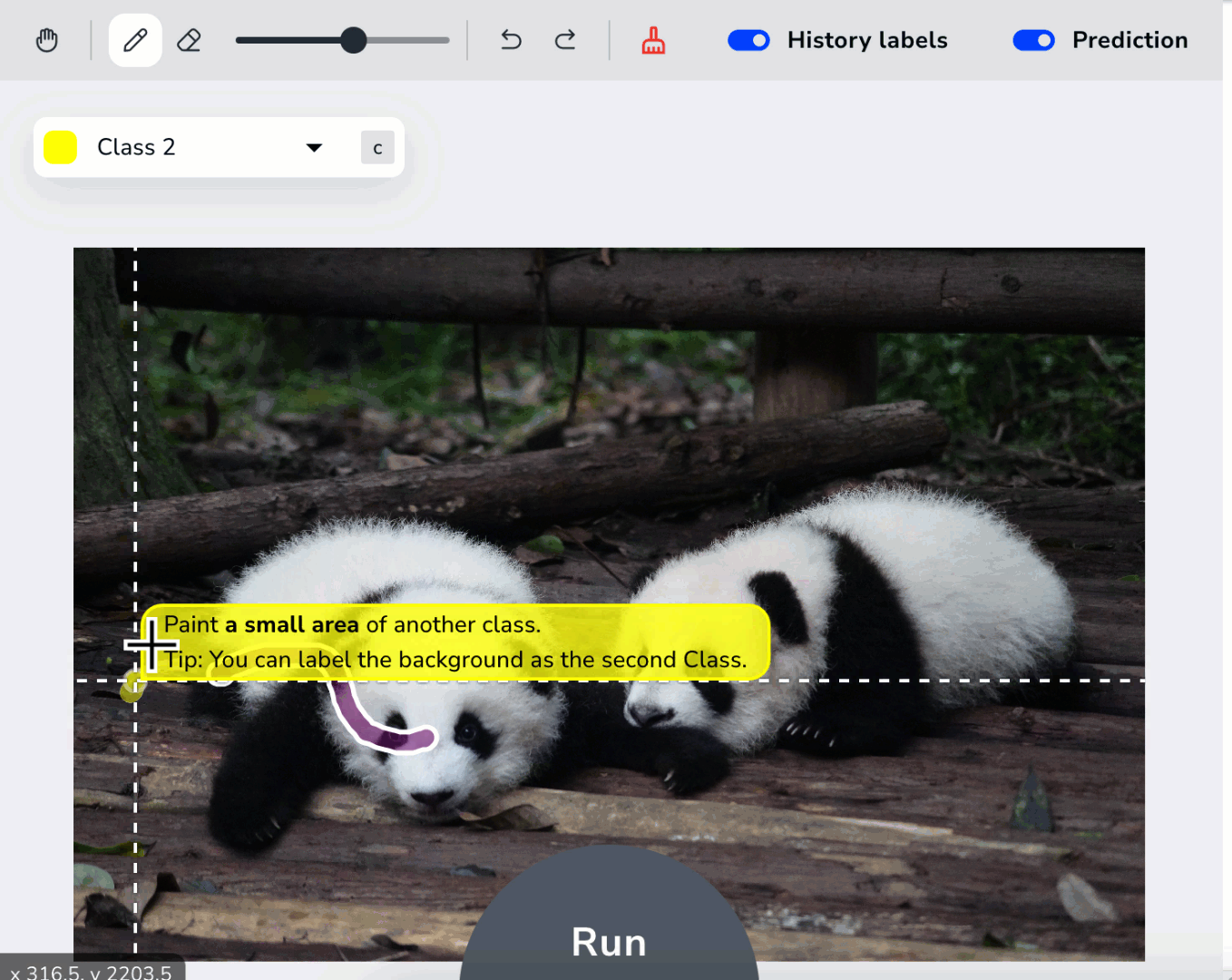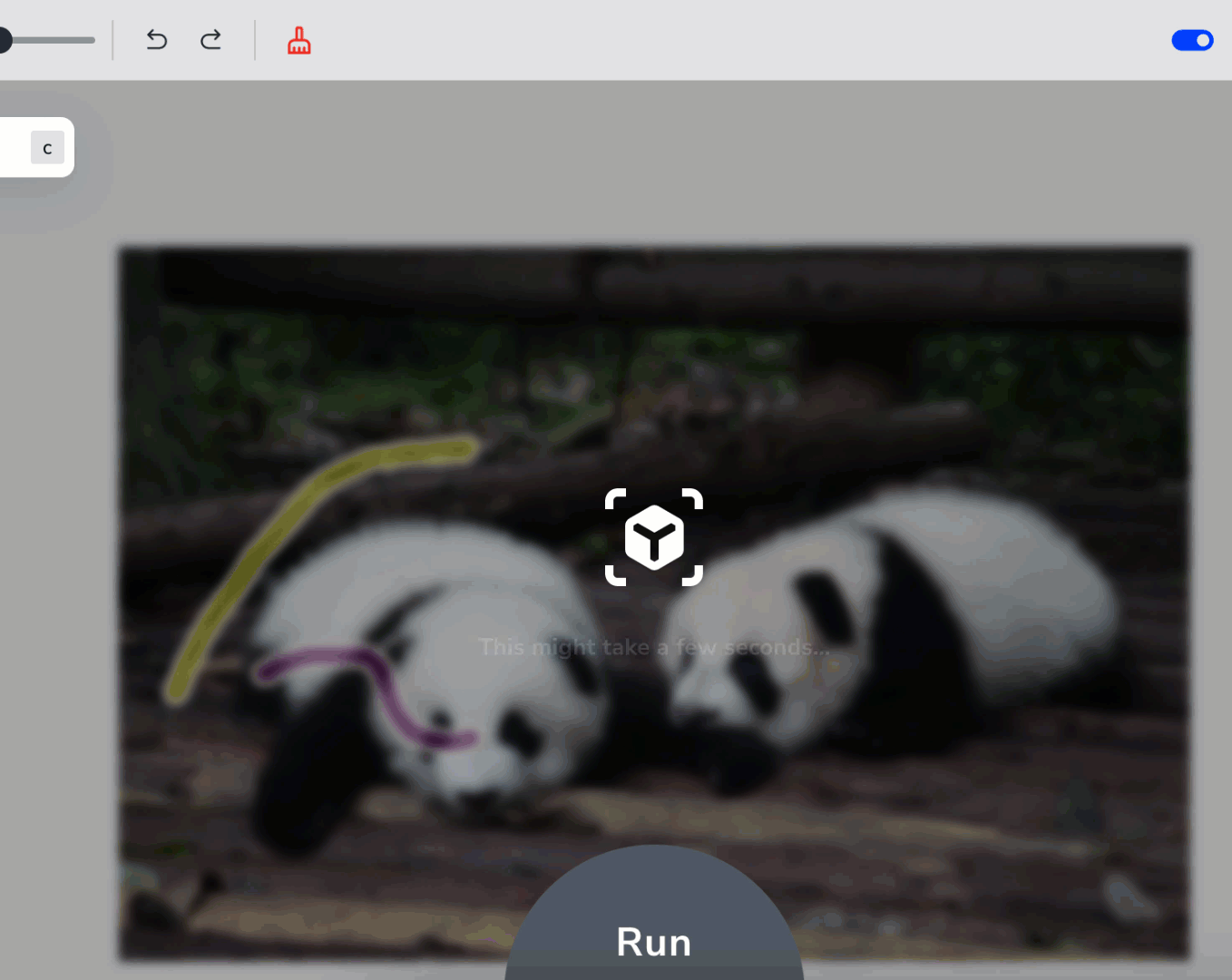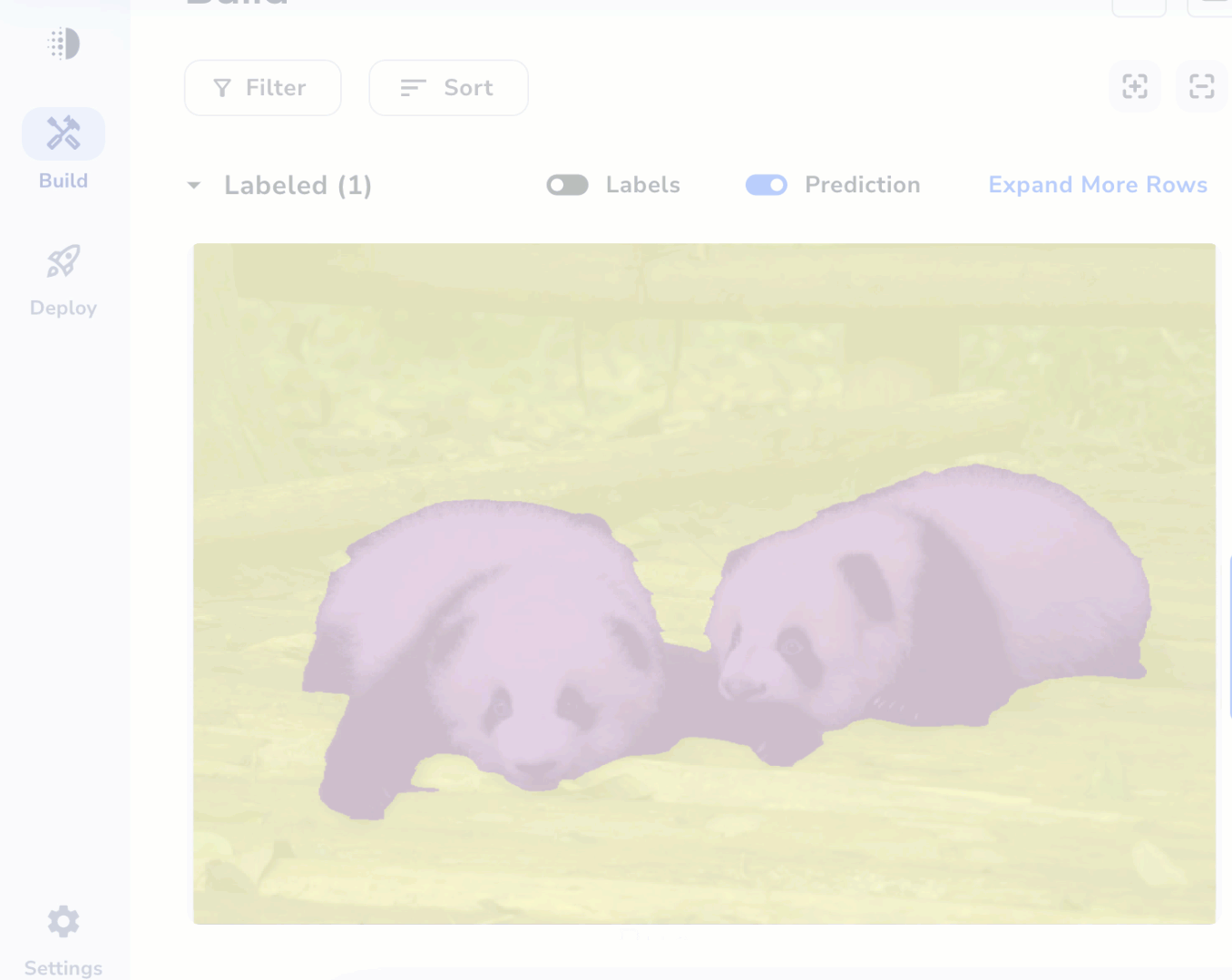
introduces a fast new way to label images called Prompting. Prompting is the act of only labeling a small area of the object you want to identify. Your model learns from each pixel you label, so it’s important that your labels are precise. Say you build a model to detect birds. Take a look at the image below. There are two classes labeled: Bird (purple) and Background (yellow). Do you notice anything wrong? If you look closely, you can see that the Bird class is not labeled precisely because the purple line stretches into the background. The model will think that portions of the background belong to the Bird class, and it won’t be able to accurately detect birds.

Label at Least Two Classes
Projects require at least two classes. By establishing two classes, the model will be able to “understand” where one class ends and another begins. Even if you only want to detect one specific object, you need to give the class some content to compare itself against. A model predicts a class for each pixel in an image. So if you had only one class, the whole image would be predicted as belonging to that class. Therefore, you must have at least two classes. If you only want to detect one object and aren’t sure what to name your second class, consider creating a class with one of these names:- Background
- Environment
- Unimportant
- Not [object]
- Nothing to Label
.png?fit=max&auto=format&n=36kddJwbyxNMn7NN&q=85&s=df4c8f112c54a348b86837c4cc16cd61) | .png?fit=max&auto=format&n=36kddJwbyxNMn7NN&q=85&s=54e5dce7f30a6408fde2687e7eec4491) |
|---|
Only Label a Few Images
doesn’t require many images. We recommend you run the model after adding labels to just one image. Review the Predictions, and relabel that image based on any incorrect predictions. Then run the model again, and view the predictions for a few other images. Label one or two more images, and run the model again. Continue to iterate like this until the predictions are accurate.Use Case: Images Are Similar
If all of your images are of the same objects, with the same backgrounds, in similar conditions (like lighting), then you will need fewer labeled images. For example, if you’re creating a model to detect issues on PCB boards on an assembly line at the same inspection point, you can expect all of the images to be very similar to each other.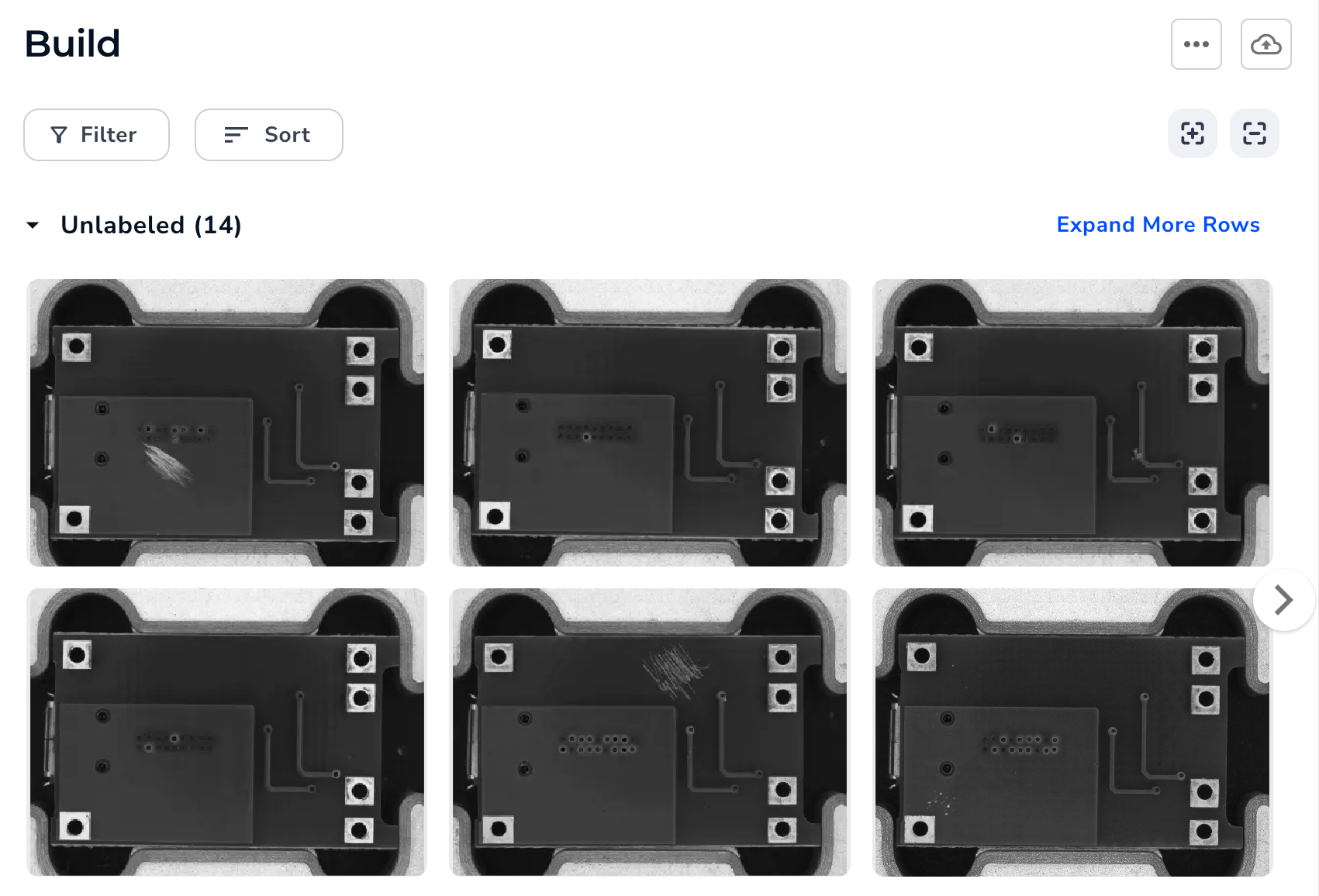
Use Case: Images Are Very Different
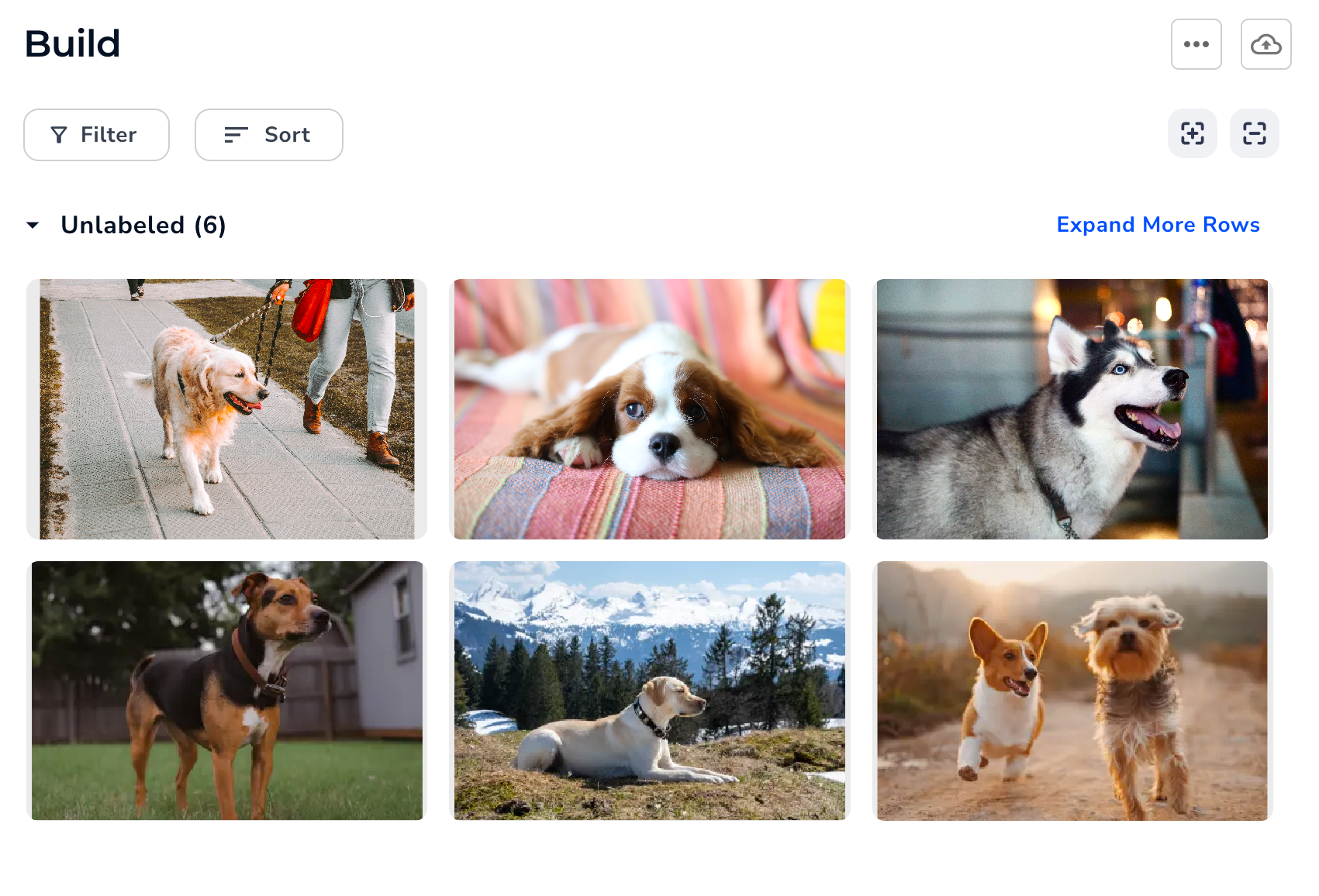
If all of your images are of different objects, with different backgrounds, in different conditions (like lighting), then you will need more labeled images. For example, if you’re creating a model to detect dogs, you will need more images to account for all the different variables. You could upload images of the following:- Different dog breeds
- Different colored dogs
- Dogs from different angles
- Dogs with collars
- Dogs without collars
- Dogs in different settings
- Dogs in sunny conditions
- Dogs in overcast conditions
Labeling Tools
LandingLens offers you several tools to help you label and navigate images. Refer to the image and table below to learn more about these tools.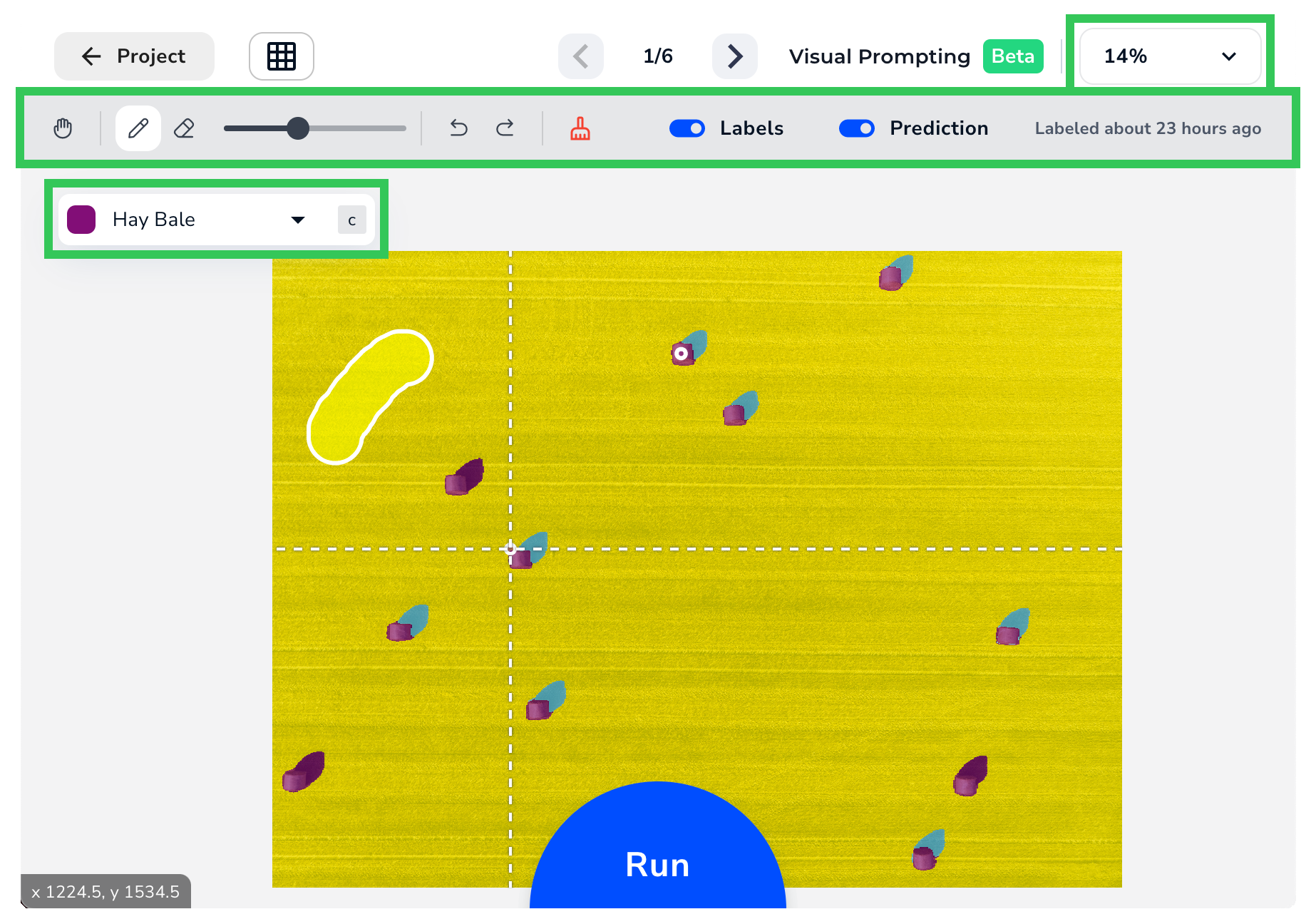
| Icon | Tool | Description | Shortcut |
|---|---|---|---|
| Zoom | Zoom in and out. | Mouse wheel up: Zoom outMouse wheel down: Zoom in | |
| Pan | Click the image and move it. This is especially useful if the image is zoomed in and you want to see part of the image that is out of the frame. | V: Select | |
| Brush | ”Paint” over an area that you want to identify. | B: Select | |
| Eraser | Remove part of a brush stroke. | E: Select | |
| Size Slider | Move the slider to change the size of the Brush or Eraser. | ]: Make larger [: Make smaller | |
| Undo | Undo the last action. | Command+Z (Mac)Ctrl+Z (Windows) | |
| Redo | Redo the action that you undid. | Shift+Command+Z (Mac)Shift+Ctrl+Z (Windows) | |
| Clear All Labels | Remove all labels from the image. | None | |
| Labels | View the labels you added. This toggle is only visible after you run the model. | None | |
| Prediction | View the predictions from the model. This toggle is only visible after you run the model. | None | |
| Class | Select a class. Any labels added with the Brush are applied to the selected class. | Up arrow key: Select the class aboveDown arrow key: Select the class below | |
| Guides | Use the white dotted guides to align the Brush or Eraser with any vertical or horizontal features. (Not marked on the image above.) | None |
Navigate Images in Labeling View
When you’re labeling an image, you can easily see and navigate to the other images in your dataset. Click the Browse Images in Sidebar icon to view the images in your dataset in a bar above the opened image. These images are grouped by whether they are Labeled or Unlabeled..png?fit=max&auto=format&n=9X4Bt4VkJz4fUiRn&q=85&s=a2409d2fc4a010dd8e57c40dbce7ee40)
.png?fit=max&auto=format&n=9X4Bt4VkJz4fUiRn&q=85&s=357b20a862c94f9063569cd962d0bc24)
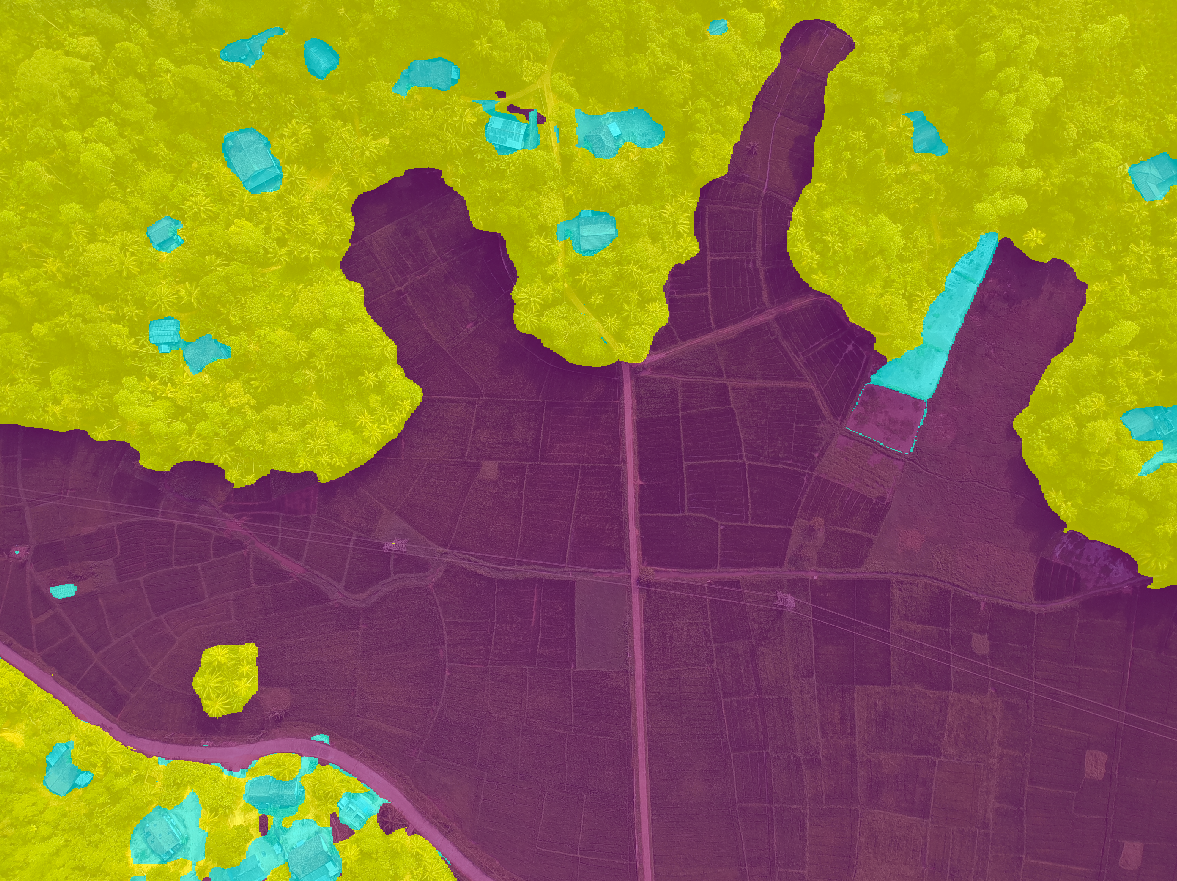
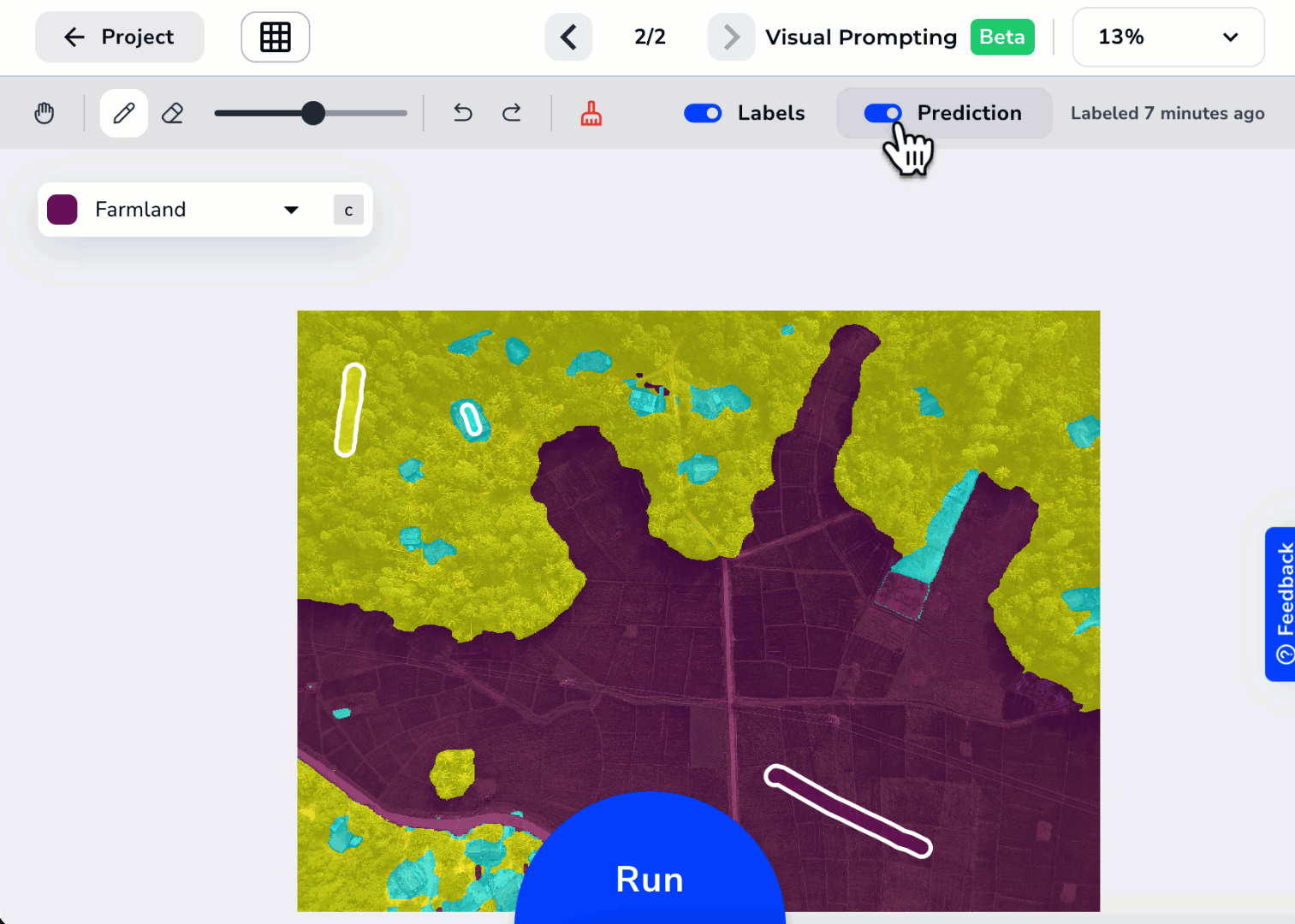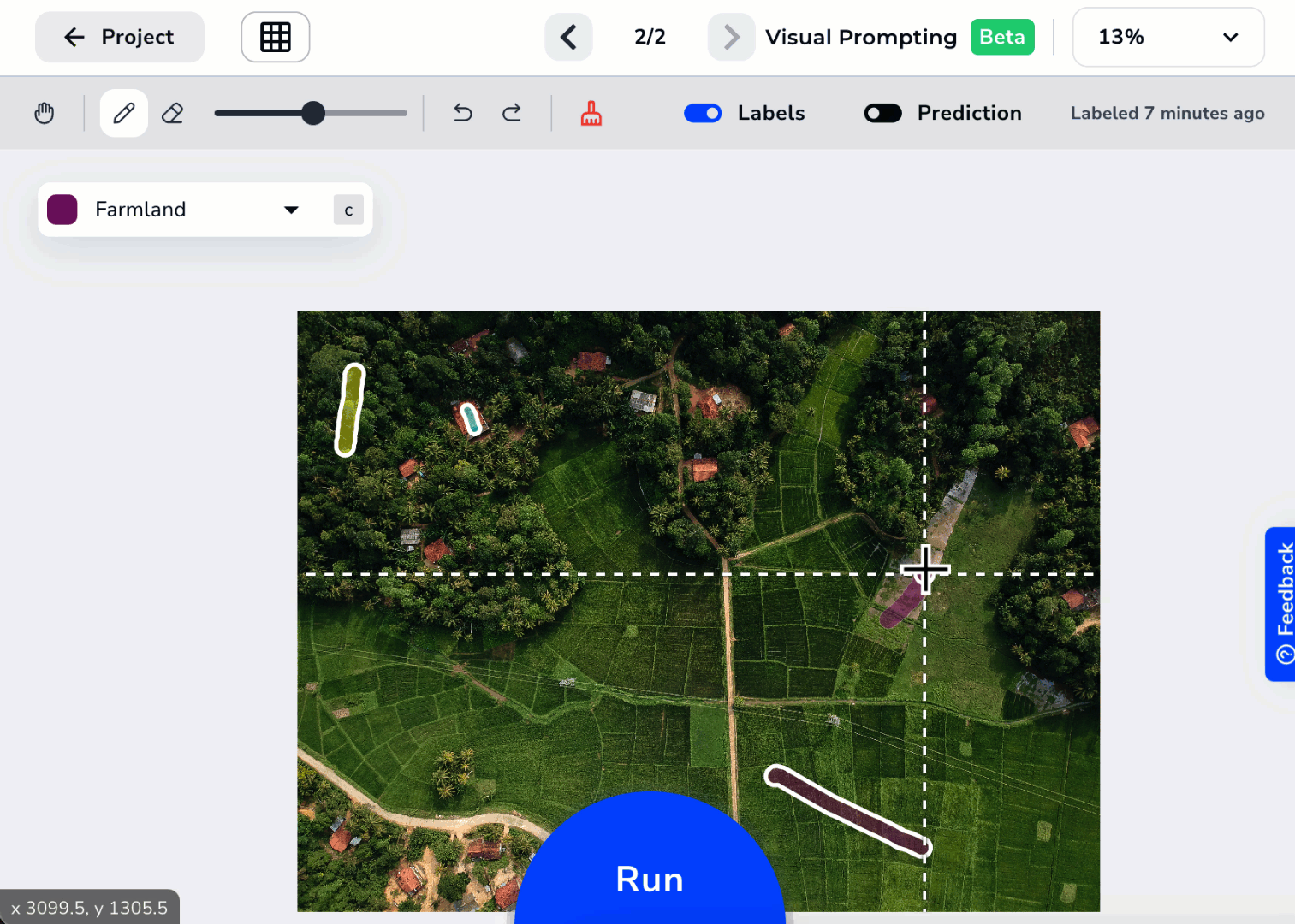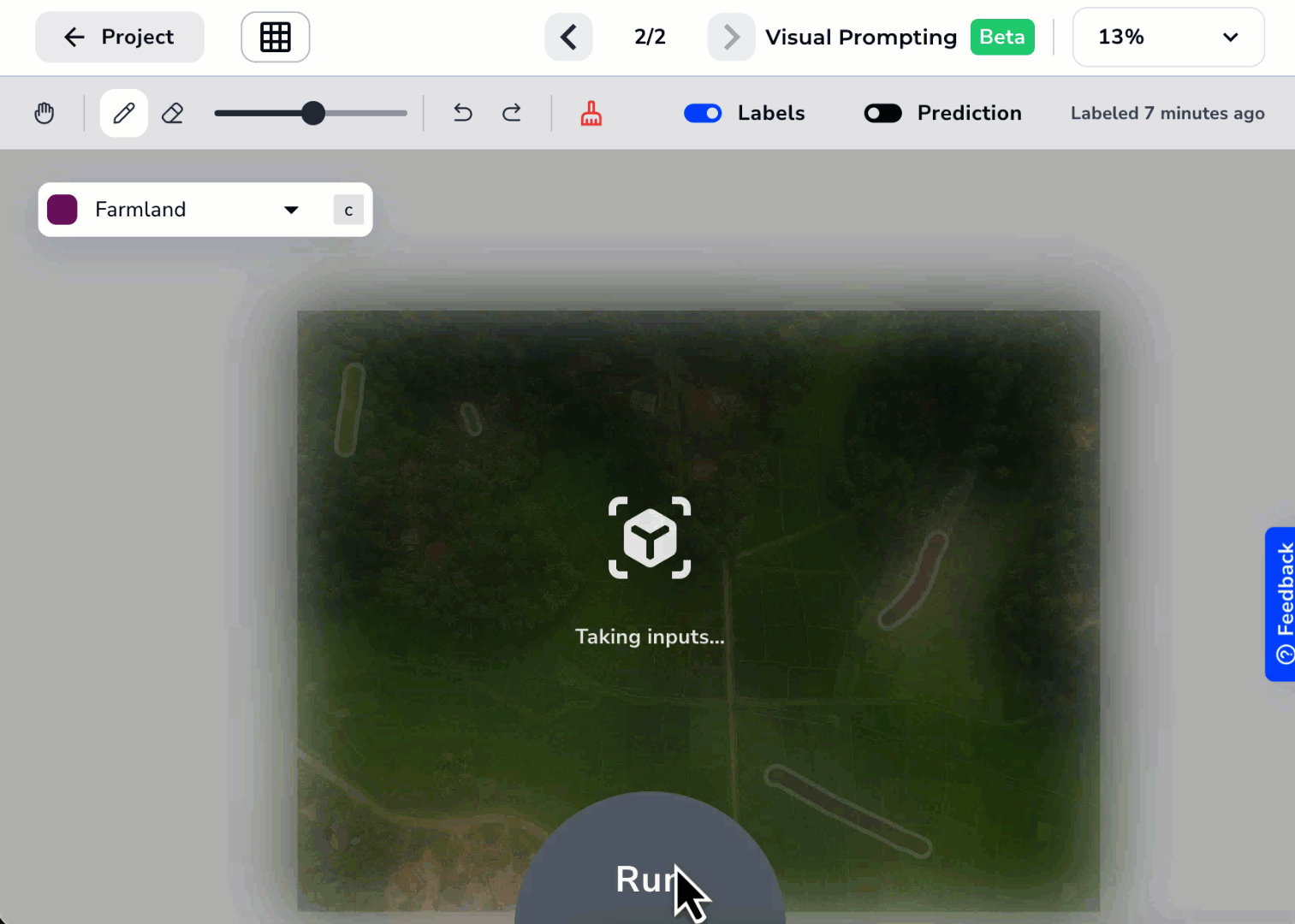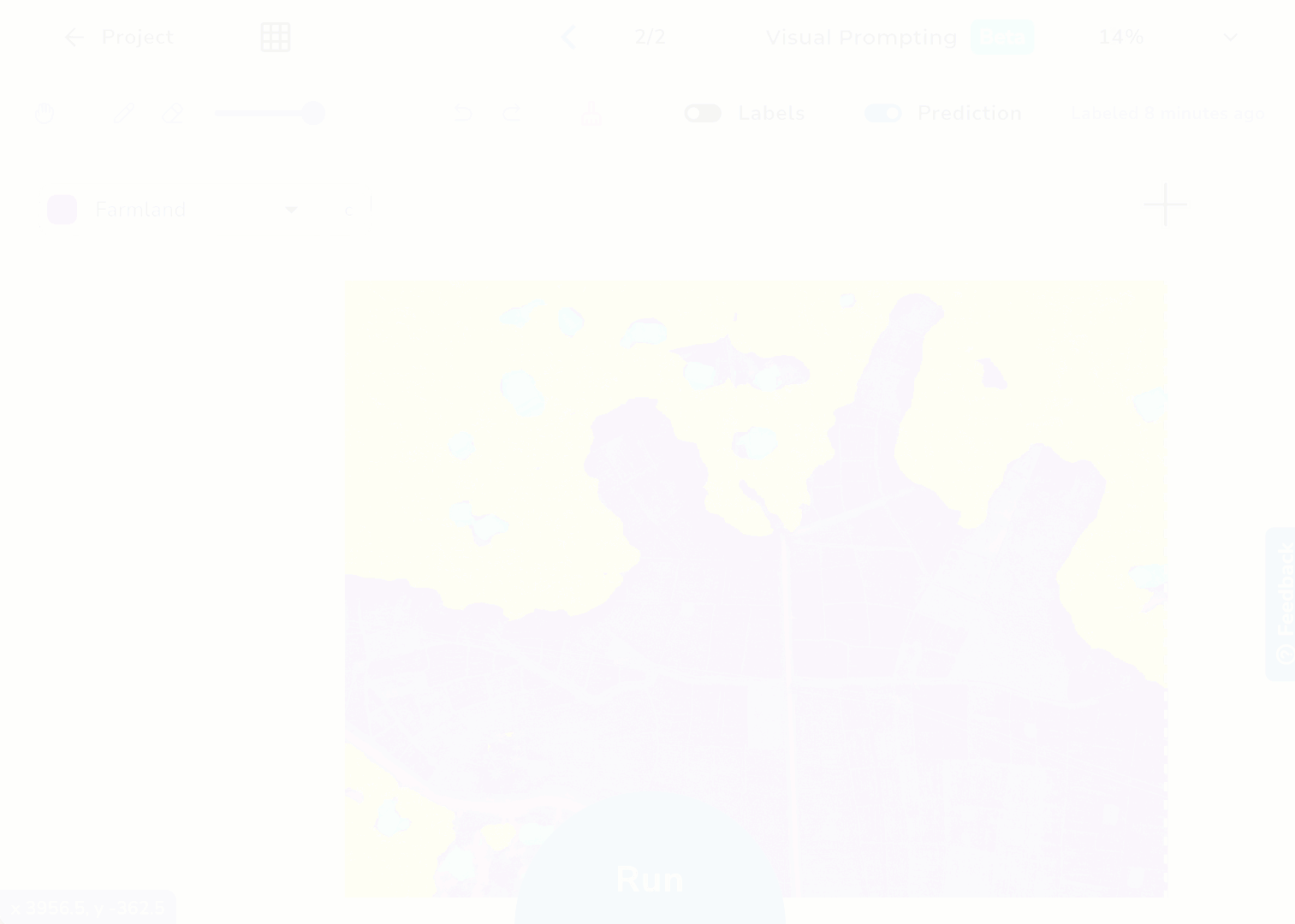
Run the Model, Review Predictions, and Iterate Your Labels
After you’ve labeled at least two classes, click Run at the bottom of the page (or press Enter).
Deploy Your Model
After you’re happy with your model, you are ready to use it! To use a model, you deploy it, which means you put the model in a virtual location so that you can upload images to it. When you upload images, the model runs inferences, which means it detects what it was trained to look for. Unlike other project types in LandingLens, you don’t need to select a specific model when deploying . This is because you’re continuously iterating on the same model, and not creating a new one each time you run the model. For detailed instructions for how to deploy models, go to Cloud Deployment.Deployment Limitations in Beta
is in beta, so we’re still ironing out a few kinks. Here are known limitations for this beta release:- The predictions in the user interface will have more distinct lines around detected objects than the predictions in the deployed model. We’re working hard to get the predictions in the deployed model as good as what you see on screen.
- Models from projects can’t be deployed in LandingEdge or Docker.
Project View
When you’re looking at and labeling an image (Labeling View), click Project to see all the images in your project.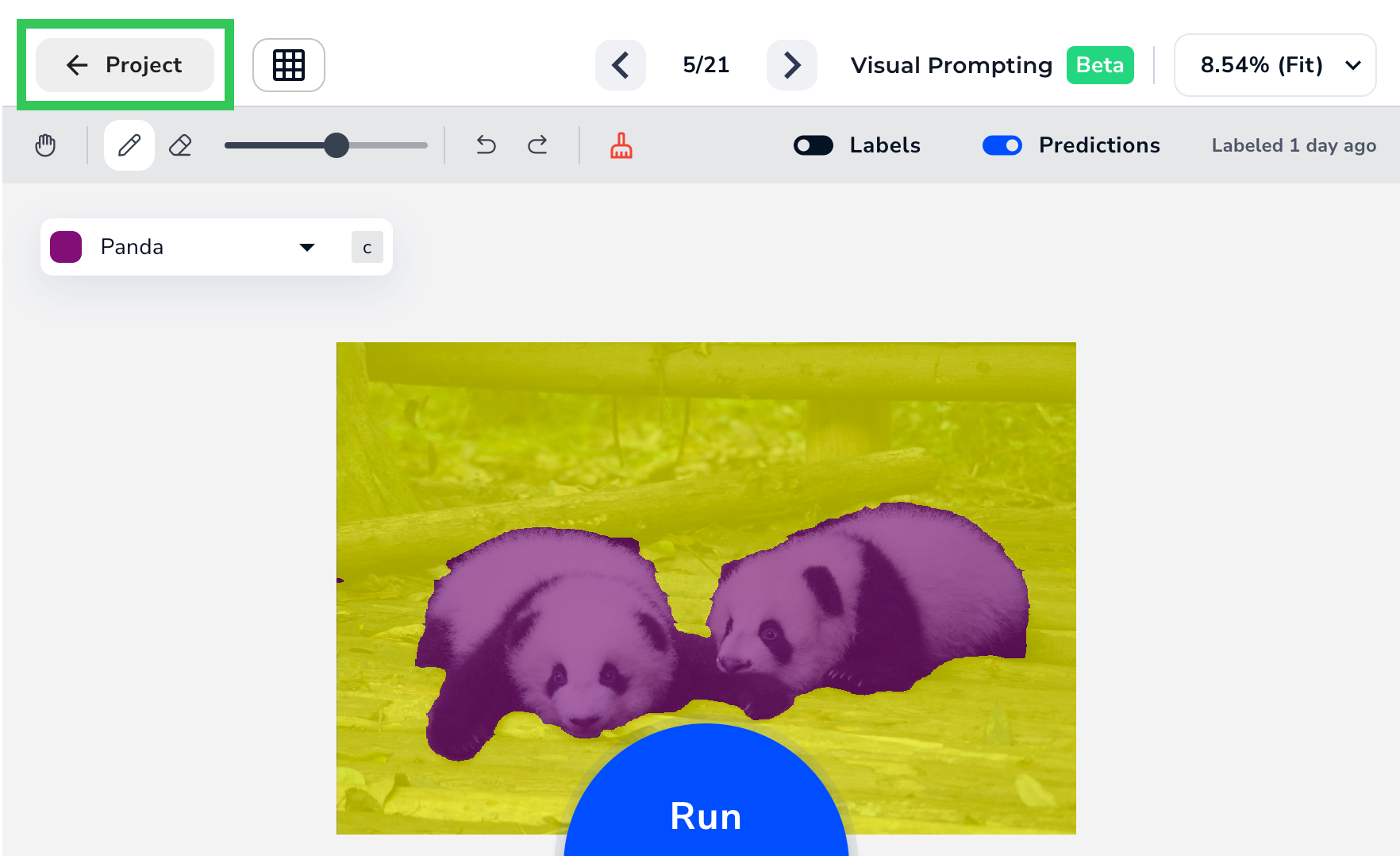
Labels and Prediction Toggles
After you’ve run your model at least once, these toggles display in both the Labeling View and Project View:- Labels: View the labels you added.
- Prediction: View the Predictions from the model.