Do not use the legacy ADE endpoint (
v1/tools/agentic-document-analysis). This endpoint will be deprecated on March 31, 2026. Use the ADE Parse endpoint instead.data.markdown field.
The markdown field contains the complete parsed document content and chunk IDs for reference.
Markdown Field in Context
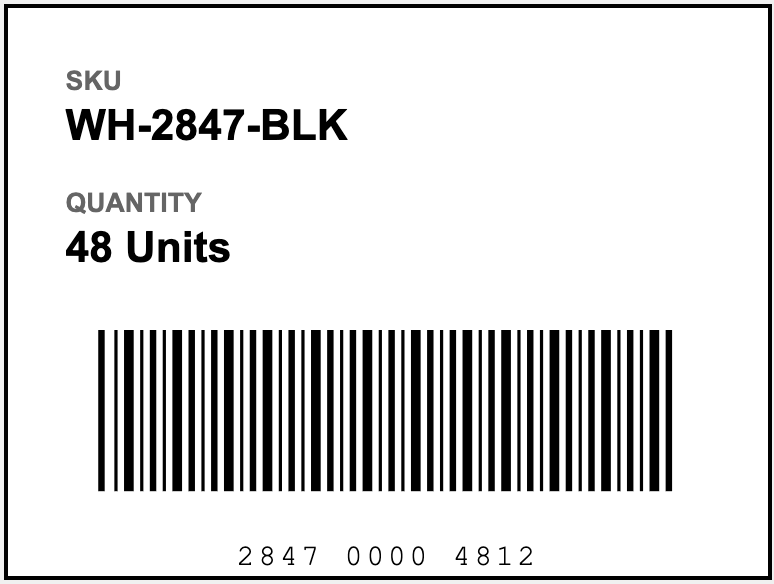
To better understand themarkdown formatting for the legacy API, let’s look at the parsing response for this pallet label:
markdown field highlighted.
Markdown Fields for Legacy API
Markdown Structure
Themarkdown field contains a sequence of chunks. Each chunk consists of the content followed by an HTML comment containing metadata.
For example, the following markdown field contains two chunks:
- A text chunk (ID:
426a3506-01d2-4e91-b201-af5f344501a7) with SKU information - A text chunk (ID:
2eeea9d5-17c7-4ea6-9373-b0da9e1f411d) with quantity information
HTML Comment Structure
Each HTML comment contains three pieces of information that map to the corresponding chunk object:| Information | Maps to | Description | Example |
|---|---|---|---|
| Chunk type | chunk_type | The type of content | text, figure, table |
| Grounding | grounding | Page number (starting at 0) and bounding box coordinates (l=left, t=top, r=right, b=bottom) | from page 0 (l=0.071,t=0.098,r=0.464,b=0.263) |
| Chunk ID | chunk_id | Unique identifier for the chunk | with ID 426a3506-01d2-4e91-b201-af5f344501a7 |