Overview
Use the API to pull specific data fields from parsed documents. You define a schema that specifies which fields to extract, and returns their values in a structured, predictable format. is designed for high-volume, repeatable workflows: use it when you need to retrieve the same set of fields from many documents, such as pulling invoice totals, contract dates, or form field values. Results are consistent across documents with varying layouts because extraction is schema-driven.Extraction Capabilities
The following capabilities are available with modelextract-20260314 or later.
- Unlimited schema size: No limits on the number of fields, nested levels, or characters in a schema.
- Semantic field matching: Use the
x-alternativeNameskeyword to define alternative labels for a field. The model maps fields by meaning, so fields with different names across documents resolve to the same schema field. - Consistent formatting: Use the
formatkeyword to specify how extracted values should be formatted. - Improved handling of large content: Better extraction from large tables, large arrays, and long documents.
- Cross-page table reconstruction: Tables that span page breaks are returned as a single array, with no post-processing needed.
Run Parse First
runs after Parse, which is required as the first step in all ADE workflows. It can also follow Split if you’re working with multi-document files.Get Started: Extraction Workflow
You can use the schema extraction wizard directly in our Playground to build and validate an extraction schema. The Playground generates scripts that you can then copy and use in your own code:- Use the schema extraction wizard in our Playground to build a schema tailored to your documents.
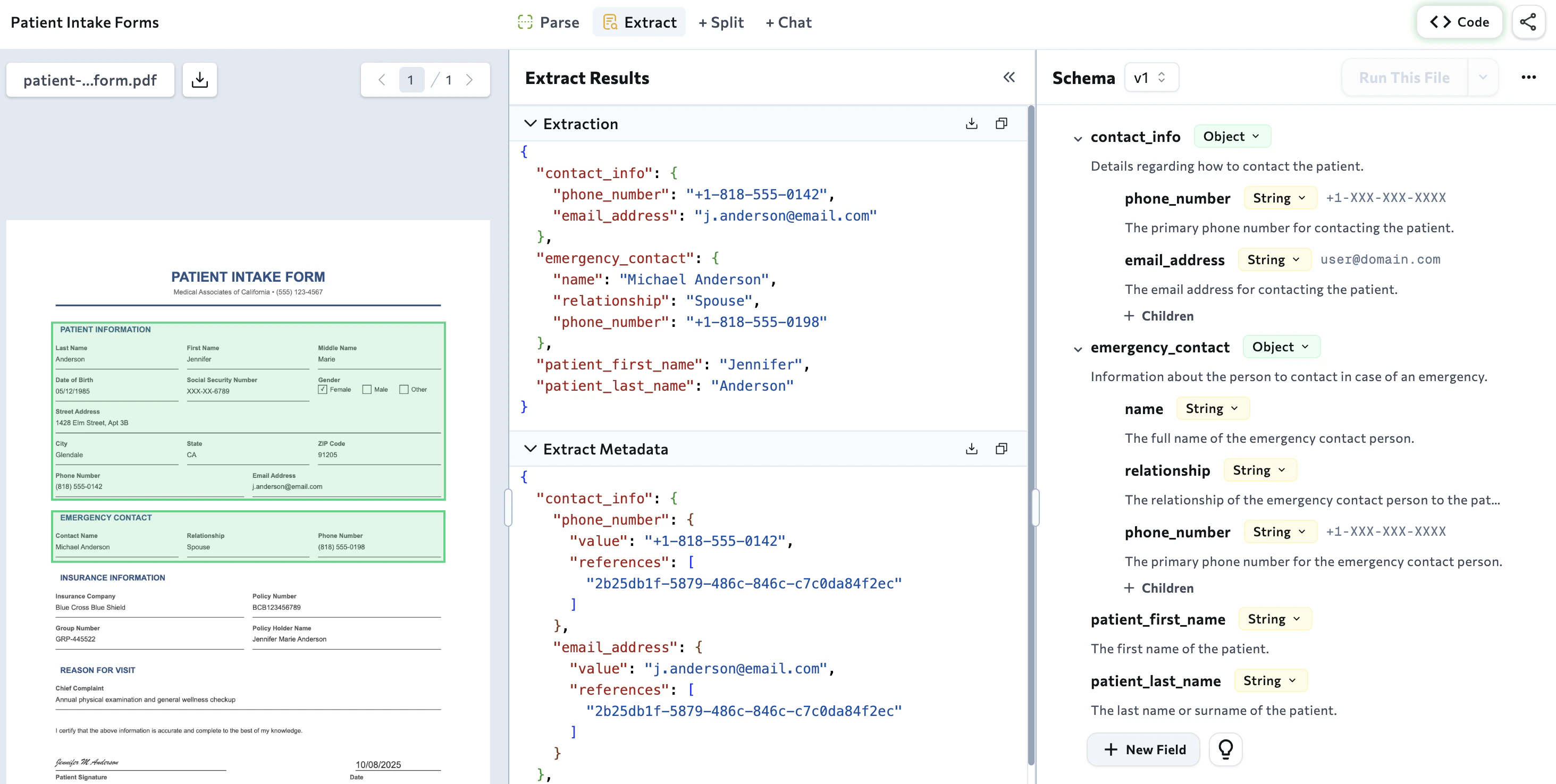
- Copy the script for the method you plan on using: the library or the API.
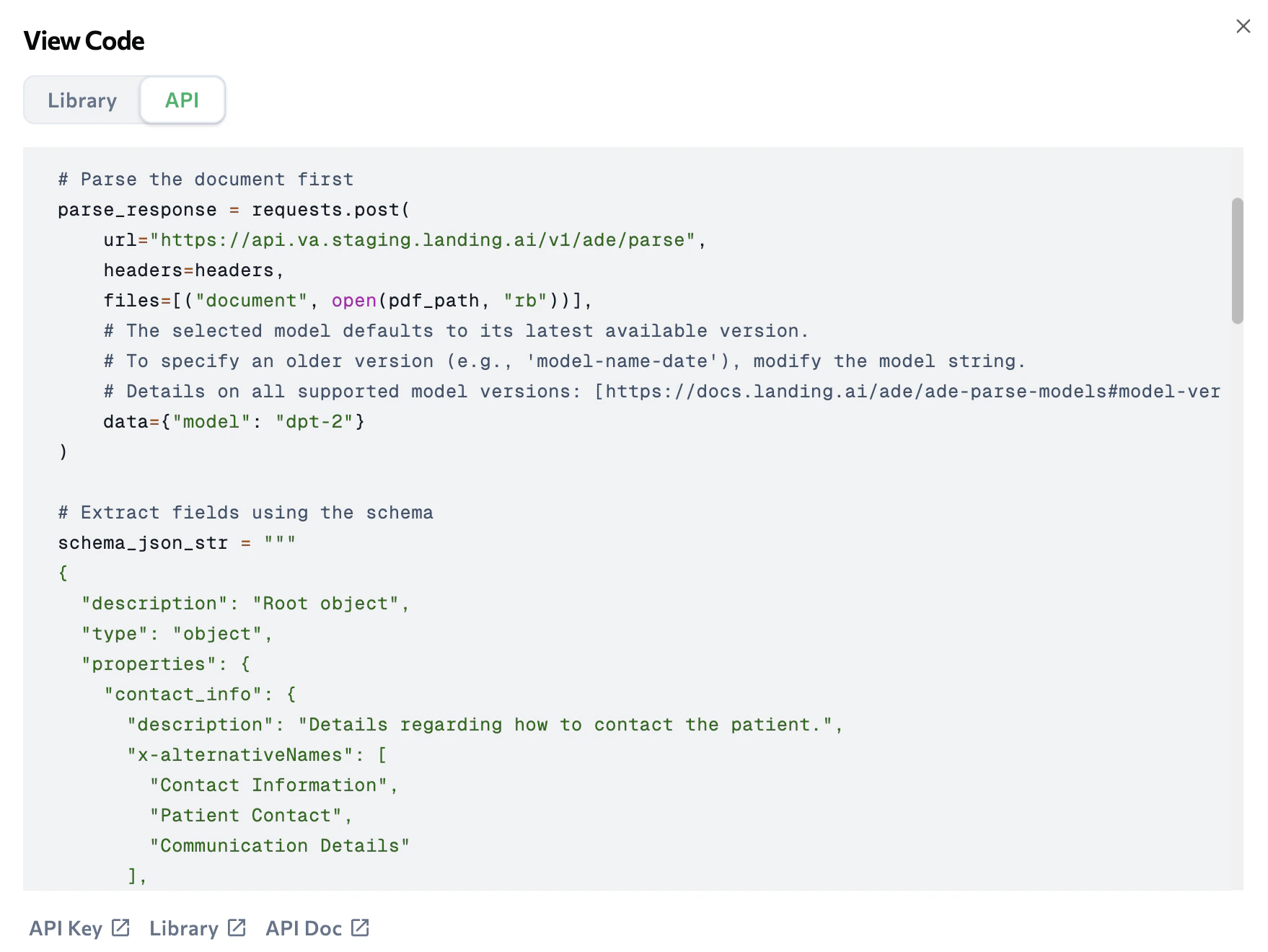
- Paste the script into your code.
Use the ADE Extract API to Extract Fields from Markdown
Use the API to extract data from the Markdown output created by the API. See the full API reference here.Specify Documents to Run Extraction On
The API offers two parameters for specifying the document you want to extract from:markdown: Specify the actual Markdown file you want to run extraction on.markdown_url: Include the URL to the Markdown file you want to run extraction on.
Set the Extraction Schema
Set the extraction schema in theschema parameter. The schema must meet specific format and property requirements. For detailed guidance, see JSON Schema for Extraction.
Set the strict Parameter
Use the optional strict parameter to control how the API handles schemas that include keywords that cause errors.
- If
strictisfalse: the API continues processing and returns a206(Partial Content). - If
strictistrue: the API stops processing and returns a422(Unprocessable Entity).
422 if the schema fails validation, and 206 if the extracted output does not conform to the schema after extraction completes.
Extracted Output
For details about the extraction response structure and fields, see JSON Response for Extraction.Run Extract with Our Libraries
Click one of the tiles below to learn how to run the API with our libraries.Python Library
Run Extract with our Python library.
TypeScript Library
Run Extract with our TypeScript library.
Use Parse Markdown for Best Results
The API is optimized for Markdown generated by the API. The parsed output includes element IDs, anchor tags, chunk tags, and other metadata that uses during the extraction process. can also process generic Markdown files or edited Parse Markdown, but results may be less accurate. For best results:- Use only Markdown output from the API, not generic Markdown files.
- Do not edit the Markdown from before passing it to .