markdown fields at three levels:
- Top-level
markdownfield: Contains the complete parsed document content as Markdown - Chunk-level
markdownfields: Each object in thechunksarray includes its ownmarkdownfield containing only the content for that specific chunk - Split-level
markdownfields: Each object in thesplitsarray includes amarkdownfield containing the content for that specific section of the document
markdown fields use the same formatting and include embedded HTML anchor tags that link the content to specific chunks in the chunks array. These anchors enable you to trace content back to its location in the original document.
Markdown Fields in Context
To better understand how thesemarkdown fields work together, let’s look at the parsing response for this pallet label:
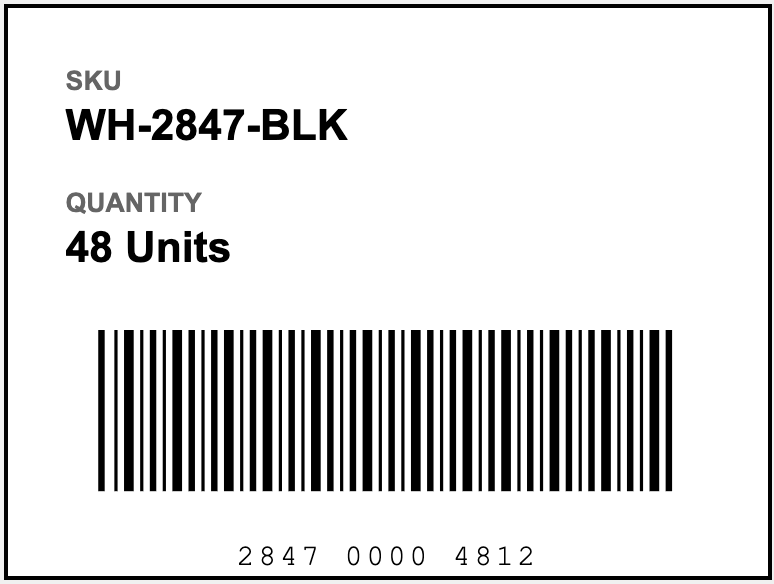
markdown fields highlighted. Notice that each chunk’s HTML anchor tag (the <a id='...'> element) appears consistently across all markdown fields.
This consistency means you can reference any chunk by its ID, whether you’re working with the complete document Markdown, a specific split, or an individual chunk.
Markdown Fields
Markdown Structure
Themarkdown field includes a parsed chunk or a sequence of chunks.
Each chunk begins with an HTML anchor tag containing a unique identifier, followed by the chunk content.
For example, the following markdown field contains two chunks:
- A figure chunk (ID:
4c29090b-b75e-4d5f-95b6-24a7d5668486) with a description of the image - A text chunk (ID:
ae2e4e41-9443-4fb5-bced-199915f97dec) containing formatted address information
Anchor Tags
Each chunk begins with an HTML anchor tag containing the chunk’s unique identifier. Theid attribute contains the UUID that matches the corresponding entry in the chunks array, enabling you to trace content back to its location in the original document.
Content Format by Chunk Type
The Markdown content format varies based on the chunk type:Text-Based Chunks
For text-based chunks (text, marginalia), content appears as standard Markdown text:
Image-Based Chunks
Image-based chunks (figure, logo, card, attestation, scan_code) use a special delimiter format that wraps the caption or description:
Table Chunks
Table chunks (table) appear as HTML table markup.
Most table elements include unique id attributes. These IDs use the format {page_number}-{base62_sequential_number}, where the page number starts at 0 and the sequential number increments for each element within the page.
If a page contains multiple tables, the ID numbering continues sequentially across all tables on that page.
Table cells that span multiple rows or columns include rowspan or colspan attributes in the HTML markup.
This ID system allows you to trace individual cells, rows, and tables back to their locations in the original document. The JSON response also includes position information (row, column, rowspan, colspan) for each table cell in the grounding object.
Spreadsheets
When you parse spreadsheets, data is identified astable chunks, and embedded images or charts are identified as figure chunks. Table chunks appear as HTML table markup.
Most table elements include unique id attributes. These IDs use the format {tab_name}-{cell_reference}, where the tab name is the name of the spreadsheet tab and the cell reference uses standard spreadsheet notation (column letter followed by row number, such as A1, B2, or C3).
The table itself uses a range-based ID format: {tab_name}-{start_cell}:{end_cell} (for example, Sheet 1-A1:B4).
This ID system allows you to trace individual cells back to their locations in the original spreadsheet.
For example, here is a screenshot of a spreadsheet, followed by the Markdown output.
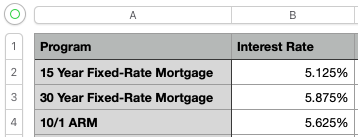
For a list of supported spreadsheet types, go to Supported File Types.
Chunk Separators
Chunks are separated by double newlines (\n\n), except for the final chunk in the document.
How do I find the Markdown response for the ADE Parse Jobs API?
If you call the ADE Parse Jobs API, the API responds with thejob_id. The parsing results, including the markdown field, are returned when you check the parsing job status with the ADE Get Parse Jobs API.